2015年5月2日 星期六
[Mac] 在OS X安裝wget
下載最新的wget
curl -O http://ftp.gnu.org/gnu/wget/wget-1.15.tar.gz
解壓縮
tar -xzf wget-1.15.tar.gz
到目錄
cd wget-1.15
偵測編譯環境
./configure --with-ssl=openssl
這邊如果出現錯誤的話就開啟xcode
再輸入一次相同的指令,即可成功
編譯程式
make
安裝程式
sudo make install
確認是否安裝成功
wget --help
清理乾淨
cd .. && rm -rf wget*
2015年4月12日 星期日
[Spark] 最近研究Spark的一些resource
 Lightning-fast cluster computing
Lightning-fast cluster computinghttp://spark.apache.org/documentation.html
官方網站總是資料最齊全的~

http://spark-summit.org/2014#videos
Spark Summit 2014 brought the Apache Spark community together on June 30- July 2, 2014 at the The Westin St. Francis in San Francisco. It featured production users of Spark, Shark, Spark Streaming and related projects.
完整的slides和vedio都可以免費觀看下載 太棒拉!!!!

2013
http://ampcamp.berkeley.edu/3/
2014
http://ampcamp.berkeley.edu/4/
Databricks Spark Reference Applications
英文版電子書~
Spark 編程指南繁體中文版
中文電子書,可以完整下載唷!!!
學長的部落格~同步學習中
http://kurthung1224.pixnet.net/blog/post/270485866
學校老師的網站
https://bigdataanalytics2014.wordpress.com/
2015年4月6日 星期一
[Spark] 在Ubuntu-14.04上安裝Spark
我在VirtualBox上實做參考的文章,寫得很詳細
sbt/sbt assembly
Install Apache Spark on Ubuntu-14.04
Building and running Spark 1.0 on Ubuntu
sbt/sbt assembly
在執行此指令時,發生了一些問題
java.io.IOException - Cannot run program "git": java.io.IOException: error=2
java.io.IOException - Cannot run program "git": java.io.IOException: error=2
解決方式為退出,並且安裝git
apt-get install git
參考
https://confluence.atlassian.com/pages/viewpage.action?pageId=297672065
apt-get install git
參考
https://confluence.atlassian.com/pages/viewpage.action?pageId=297672065
2015年3月29日 星期日
[Paper Note] 正在讀Spark相關的paper
正在讀Spark偏系統面的paper
Jakovits, P. ; Inst. of Comput. Sci., Univ. of Tartu, Tartu, Estonia ; Srirama, S.N.
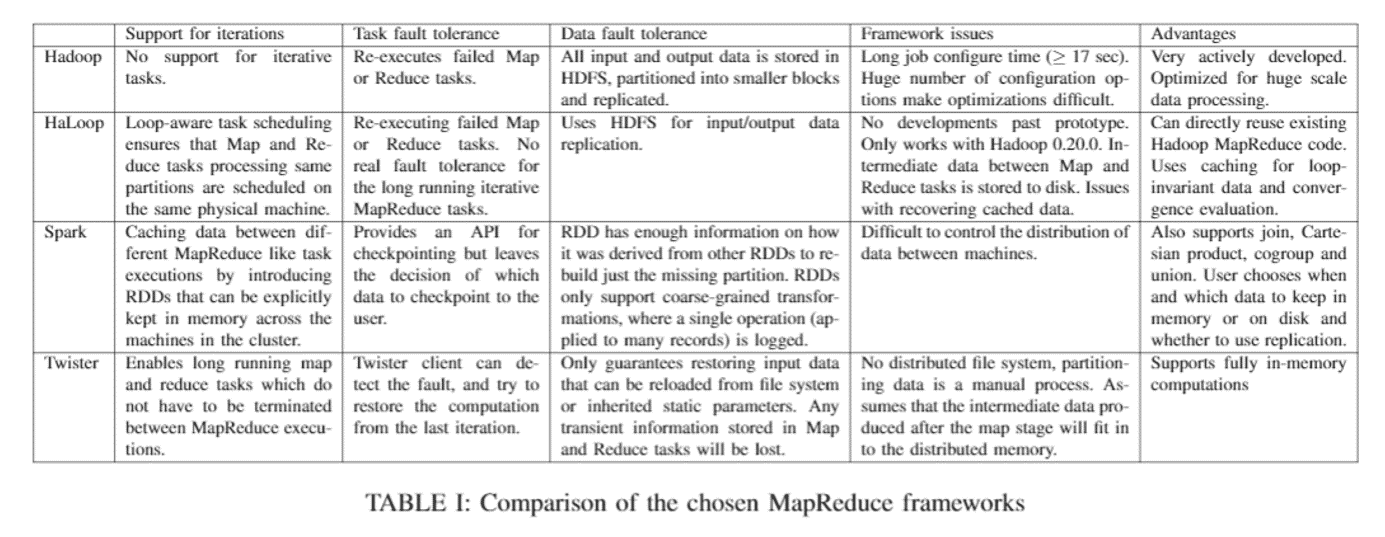
Tao Jiang ; SKL Comput. Archit., ICT, Beijing, China ; Qianlong Zhang ; Rui Hou ; Lin Chai
more authors
Spark-based anomaly detection over multi-source VMware performance data in real-time
Solaimani, M. ; Dept. of Comput. Sci., Univ. of Texas at Dallas, Richardson, TX, USA ; Iftekhar, M. ; Khan, L. ; Thuraisingham, B.
more authors
more authors
Anomaly detection refers to identifying the patterns in data that deviate from expected behavior. These non-conforming patterns are often termed as outliers, malwares, anomalies or exceptions in different application domains. This paper presents a novel, generic real-time distributed anomaly detection framework for multi-source stream data. As a case study, we have decided to detect anomaly for multi-source VMware-based cloud data center. The framework monitors VMware performance stream data (e.g., CPU load, memory usage, etc.) continuously. It collects these data simultaneously from all the VMwares connected to the network. It notifies the resource manager to reschedule its resources dynamically when it identifies any abnormal behavior of its collected data. We have used Apache Spark, a distributed framework for processing performance stream data and making prediction without any delay. Spark is chosen over a traditional distributed framework (e.g.,Hadoop and MapReduce, Mahout, etc.) that is not ideal for stream data processing. We have implemented a flat incremental clustering algorithm to model the benign characteristics in our distributed Spark based framework. We have compared the average processing latency of a tuple during clustering and prediction in Spark with Storm, another distributed framework for stream data processing. We experimentally find that Spark processes a tuple much quicker than Storm on average.
Published in:
Computational Intelligence in Cyber Security (CICS), 2014 IEEE Symposium onDate of Conference:
9-12 Dec. 2014Evaluating MapReduce frameworks for iterative Scientific Computing applications
http://ieeexplore.ieee.org/xpl/articleDetails.jsp?tp=&arnumber=6903690&searchWithin%3Dhadoop%26refinements%3D4291944246%2C4291944822%26sortType%3Ddesc_p_Citation_Count%26ranges%3D2012_2015_p_Publication_Year%26queryText%3DSPARKJakovits, P. ; Inst. of Comput. Sci., Univ. of Tartu, Tartu, Estonia ; Srirama, S.N.
Scientific Computing deals with solving complex scientific problems by applying resource-hungry computer simulation and modeling tasks on-top of supercomputers, grids and clusters. Typical scientific computing applications can take months to create and debug when applying de facto parallelization solutions like Message Passing Interface (MPI), in which the bulk of the parallelization details have to be handled by the users. Frameworks based on the MapReduce model, like Hadoop, can greatly simplify creating distributed applications by handling most of the parallelization and fault recovery details automatically for the user. However, Hadoop is strictly designed for simple, embarrassingly parallel algorithms and is not suitable for complex and especially iterative algorithms often used in scientific computing. The goal of this work is to analyze alternative MapReduce frameworks to evaluate how well they suit for solving resource hungry scientific computing problems in comparison to the assumed worst (Hadoop MapReduce) and best case (MPI) implementations for iterative algorithms.
Published in:
High Performance Computing & Simulation (HPCS), 2014 International Conference onDate of Conference:
21-25 July 2014Understanding the behavior of in-memory computing workloads
http://ieeexplore.ieee.org/xpl/articleDetails.jsp?tp=&arnumber=6983036&searchWithin%3Dhadoop%26refinements%3D4291944246%2C4291944822%26sortType%3Ddesc_p_Citation_Count%26ranges%3D2012_2015_p_Publication_Year%26queryText%3DSPARKTao Jiang ; SKL Comput. Archit., ICT, Beijing, China ; Qianlong Zhang ; Rui Hou ; Lin Chai
more authors
The increasing demands of big data applications have led researchers and practitioners to turn to in-memory computing to speed processing. For instance, the Apache Spark framework stores intermediate results in memory to deliver good performance on iterative machine learning and interactive data analysis tasks. To the best of our knowledge, though, little work has been done to understand Spark's architectural and microarchitectural behaviors. Furthermore, although conventional commodity processors have been well optimized for traditional desktops and HPC, their effectiveness for Spark workloads remains to be studied. To shed some light on the effectiveness of conventional generalpurpose processors on Spark workloads, we study their behavior in comparison to those of Hadoop, CloudSuite, SPEC CPU2006, TPC-C, and DesktopCloud. We evaluate the benchmarks on a 17-node Xeon cluster. Our performance results reveal that Spark workloads have significantly different characteristics from Hadoop and traditional HPC benchmarks. At the system level, Spark workloads have good memory bandwidth utilization (up to 50%), stable memory accesses, and high disk IO request frequency (200 per second). At the microarchitectural level, the cache and TLB are effective for Spark workloads, but the L2 cache miss rate is high. We hope this work yields insights for chip and datacenter system designers.
Published in:
Workload Characterization (IISWC), 2014 IEEE International Symposium onDate of Conference:
26-28 Oct. 2014A Big Data Architecture for Large Scale Security Monitoring
Marchal, S. ; SnT, Univ. of Luxembourg, Luxembourg, Luxembourg ; Xiuyan Jiang ; State, R. ; Engel, T.
Network traffic is a rich source of information for security monitoring. However the increasing volume of data to treat raises issues, rendering holistic analysis of network traffic difficult. In this paper we propose a solution to cope with the tremendous amount of data to analyse for security monitoring perspectives. We introduce an architecture dedicated to security monitoring of local enterprise networks. The application domain of such a system is mainly network intrusion detection and prevention, but can be used as well for forensic analysis. This architecture integrates two systems, one dedicated to scalable distributed data storage and management and the other dedicated to data exploitation. DNS data, NetFlow records, HTTP traffic and honeypot data are mined and correlated in a distributed system that leverages state of the art big data solution. Data correlation schemes are proposed and their performance are evaluated against several well-known big data framework including Hadoop and Spark.
Published in:
Big Data (BigData Congress), 2014 IEEE International Congress onDate of Conference:
June 27 2014-July 2 20142015年3月27日 星期五
[Hadoop] 開啟或關閉hadoop
開啟或關閉hadoop
把hadoop關掉(master)
stop-all.sh
刪掉hadoop暫存檔
\rm -r /opt/hadoop/tmp
登入slave01
ssh slave01
\rm -r /opt/hadoop/tmp
exit //離開slave01
登入slave02
ssh slave02
\rm -r /opt/hadoop/tmp
exit //離開slave02回到master
把namenode格式化,讓master重新認識namenode
hadoop namenode -format
啟動hadoop
start-all.sh
確認有沒有開啟hadoop
http://[master01 IP]:50070/
確認MapReduce的狀況
http://[master01 IP]:8088/
jps //類似工作管理員,看有哪些東西在run
把hadoop關掉(master)
stop-all.sh
刪掉hadoop暫存檔
\rm -r /opt/hadoop/tmp
登入slave01
ssh slave01
\rm -r /opt/hadoop/tmp
exit //離開slave01
登入slave02
ssh slave02
\rm -r /opt/hadoop/tmp
exit //離開slave02回到master
把namenode格式化,讓master重新認識namenode
hadoop namenode -format
啟動hadoop
start-all.sh
確認有沒有開啟hadoop
http://[master01 IP]:50070/
確認MapReduce的狀況
http://[master01 IP]:8088/

jps //類似工作管理員,看有哪些東西在run
hadoop dfsadmin -report //查看群集狀態
[參考資料]
Hadoop 2.2.0 Single Cluster 安裝 (二)(CentOS 6.4 x64)
http://shaurong.blogspot.tw/2013/11/hadoop-220-single-cluster-centos-64-x64_7.html
CentOS 安装 hadoop(伪分布模式)
http://zhans52.iteye.com/blog/1102649
[參考資料]
Hadoop 2.2.0 Single Cluster 安裝 (二)(CentOS 6.4 x64)
http://shaurong.blogspot.tw/2013/11/hadoop-220-single-cluster-centos-64-x64_7.html
CentOS 安装 hadoop(伪分布模式)
http://zhans52.iteye.com/blog/1102649
在Mac上使用ssh
在Windows我們常使用putty,不過Mac卻不支援
那要如何在Mac上使用ssh呢?
首先要打開terminal,請輸入:
ssh root@IP
ex: ssh root@192.168.70.101
指定port,請輸入:
ssh root@IP -p port
ex: ssh root@192.168.70.101 -p 22
那要如何在Mac上使用ssh呢?
首先要打開terminal,請輸入:
ssh root@IP
ex: ssh root@192.168.70.101
指定port,請輸入:
ssh root@IP -p port
ex: ssh root@192.168.70.101 -p 22

訂閱:
文章 (Atom)